Форсайт и искусственный интеллект
Благодаря машинному обучению, плоды среднесрочного технологического форсайта имеют все шансы в недалёком будущем превратиться в коммодити на информационных рынках. Но покамест форсайтеры-люди ходят гоголем и просят солидные гонорары.
Не могло быть, чтобы от скрещивания кривой Гартнера с форсайтом не родились какие-нибудь дети.
Два молодых китайских учёных из Государственной научной библиотеки Академии наук Китая Шяли Чен (Xiaoli Chen) и Тао Хан (Tao Han) на конференции TEMSCON, которую проводил в июне 2019 в Атланте Institute of Electrical and Electronics Engineers (IEEE), представили доклад о том, как тестировали алгоритмы машинного обучения с учителем (supervised machine learning) для раннего выявления «потенциально подрывных» (potentially disruptive) технологий [1].
Главная идея: поскольку для надёжного предсказания будущего необходимо собирать и интепретировать колоссальное количество факторов, искусственный интеллект способен делать это лучше человека. Алгоритмы машинной интерпретации, запитываемые данными «вручную» [2-4], как и алгоритмы автоматического сбора данных с человеческим – экспертным – синтезом уже применялись в форсайте [5-8]. Но Шяли Чен и Тао Хан решили задействовать ИИ как для непрерывного получения данных из многочисленных источников, так и для анализа и интерпретации. Вероятно, ими двигало стремление полностью устранить человека из форсайта и превратить прогнозы если не в коммодити, то в добротный товар, продаваемый по доступным ценам на информационных рынках.
Я подозреваю Шяли Чен и Тао Хана в замахе на многофакторное прогнозирование будущего, а не только на выявление подрывных технологий, несмотря на то, что в статье они фокусируют себя довольно узко. Пройдясь с помощью цитаты [9] по «Дилемме инноватора» за то, что из 77 технологий, названных в книге подрывными, лишь 7 отвечают критериям такого статуса, сформулированным самим же Кристенсеном, Шяли и Тао предложили собственные признаки потенциально подрывной технологии, которые и заложили в свою модель:
1. Должна наличествовать «подрываемая» технология (или, чаще, технологии).
2. Подрывная технология значительно быстрее, чем стабильная (sustainable), достигает оптимума эффективности.
3. Подрывная технология влечёт за собой существенные социально-экономические последствия.
То есть, deus ex-machina, задуманный Шяли и Тао для исследования технологий, на деле будет появляться на сцене с вестями о больших переменах в жизни множества людей.
Шяли Чен и Тао Хана по сути своих занятий – библиотекари. Поэтому из всего пантеона методов форсайта они выбрали библиометрику, хорошо алгоритмизируемый количественный доказательный метод. Организовав автоматический сбор данных для своей модели из Google Trends, Google Book Ngram, научных статей Scopus и Бюро патентов США, китайские исследователи обратились к экспертам-людям для того, чтобы те постфактум маркировали 387 состоявшихся технологий из списка Gartner Hype Cycle за период 1995-2018 как «подрывные» и «обычные». Таким образом были подготовлены данные и эталонная категоризация для машинного обучения.
История, увы, обрывается на самом интересном месте. Шяли и Тао протестировали и сравнили четыре алгоритма обучения, использовав кривую Гартнера и мнения экспертов в качестве «учебного пособия» для ИИ. Доклад китайских товарищей констатирует, что один из алгоритмов превосходит другие (но не решающе) и теперь необходимо продолжить исследования в направлении машинного форсайта. Какие конкретно потенциально подрывные технологии выявил их цифровой ученик в результате обучения, на конференции в Атланте сказано не было.
Очень любопытен один из источников, на который ссылаются Шяли Чен и Тао Хан, – британский Intellectual Property Office. В 2010 году он предложил использовать для форсайта подрывных технологий «автоматический алгоритм патентного поиска, тренируемый путём экспертной настройки весовых коэффициентов на базе ретроспективной модели» [10]. Во-первых, это вполне доступная для реализации в домашних условиях штука (разве что страшно звучит). Во-вторых, британцы предлагают с помощью их алгоритма обнаруживать на дальних подступах не только подрывные технологии, но и технологии «двойного бума» (double boom), что, на мой взгляд, ценно, так как последние представляют очевидный стратегический интерес для компаний. (Что такое технологии "двойного бума" объясняется в [11].)
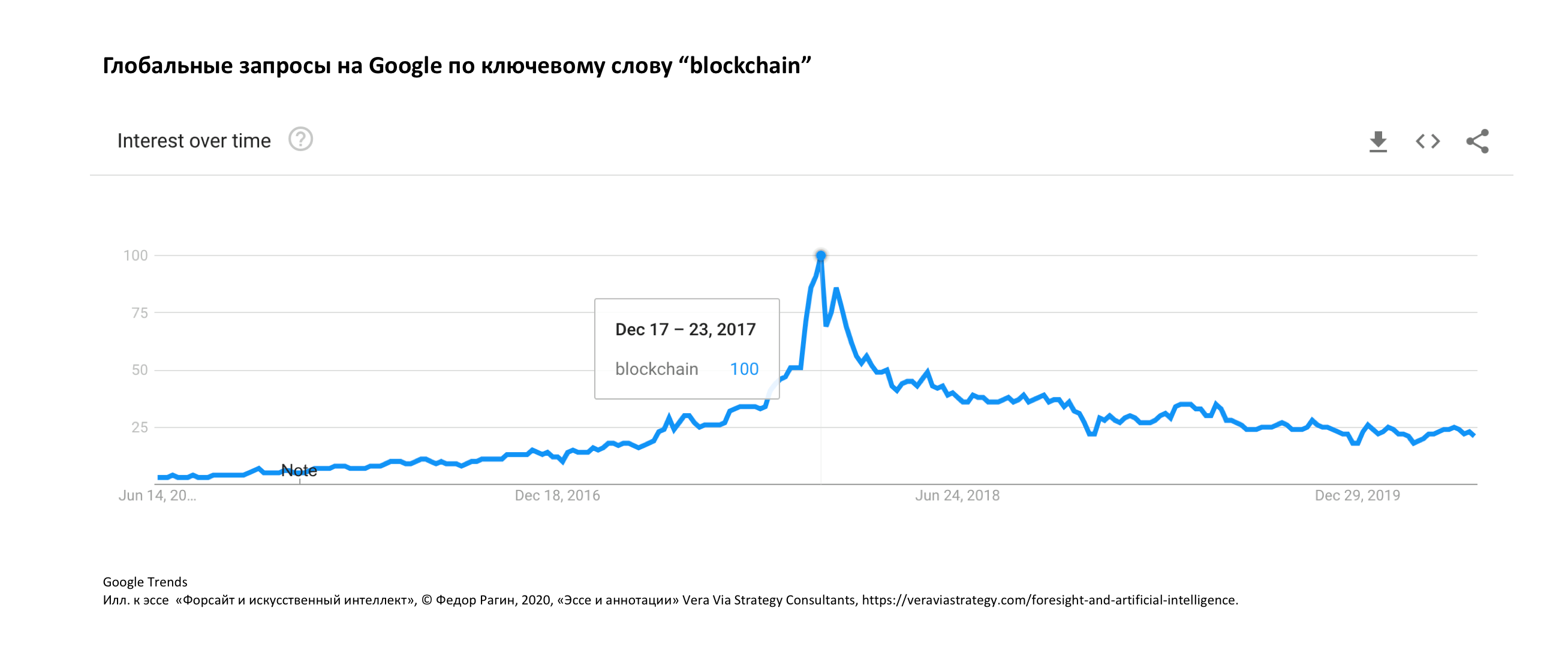
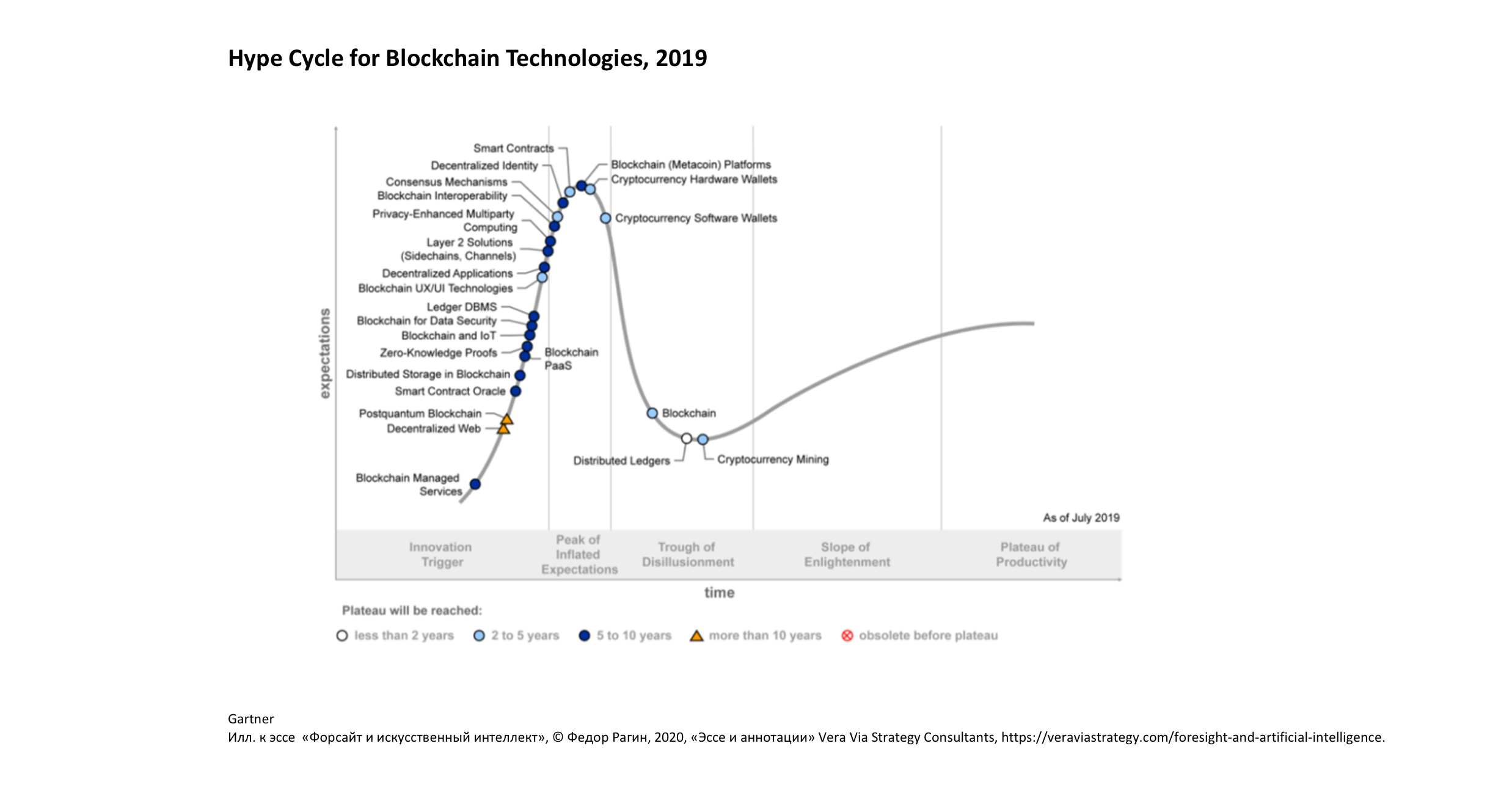
Написал я всё это потому, что сегодня мне приснилось, будто мы живём в мире победившего блокчейна, где все транзакции необратимы. Проснувшись, я полез в Google Trends, оттуда пошёл к Гартнеру, который успокоил: у нас ещё есть от 2 до 5 лет (см. картинки).
[1] X. Chen and T. Han, "Disruptive Technology Forecasting based on Gartner Hype Cycle," 2019 IEEE Technology & Engineering Management Conference (TEMSCON), Atlanta, GA, USA, 2019, pp. 1-6, doi: 10.1109/TEMSCON.2019.8813649
[2] Sasaki, Hiroshi. (2015). Simulating Hype Cycle Curves with Mathematical Functions : Some Examples of High-Tech Trends in Japan. International Journal of Managing Information Technology. 7. 1-12. https://doi.org/10.5121/ijmit.2015.7201
[3] K. Jari and T. Lauraéus, “Analysis of 2017 Gartner’s Three Megatrends to Thrive the Disruptive Business, Technology Trends 2008-2016, Dynamic Capabilities of VUCA and Foresight Leadership Tools,” Adv. Technol. Innov., vol. 4, no. 2, pp. 105–115, 2019. http://ojs.imeti.org/index.php/AITI/article/view/2521
[4] F. Hashemi, O. Gallay, and M. Hongler, “Hype Cycle Dynamics: Microscopic Modeling and Detection,” pp. 1–12, 2018. https://www.researchgate.net/publication/327744610
[5] C. Lee, O. Kwon, M. Kim, and D. Kwon, “Early identification of emerging technologies: A machine learning approach using multiple patent indicators,” Technol. Forecast. Soc. Change, vol. 127, no. October 2017, pp. 291–303, 2018. https://doi.org/10.1016/j.techfore.2017.10.002
[6] Haq, Inaam & Li, Qianmu & Hassan, Shoaib. (2019). Text Mining Techniques to Capture Facts for Cloud Computing Adoption and Big Data Processing. IEEE Access. 7. 1-1. 10.1109/ACCESS.2019.2950045
[7] A. Pilkington, “Exploring the disruptive nature of disruptive technology,” in IEEM 2009 - IEEE International Conference on Industrial Engineering and Engineering Management, 2009, pp. 1895–1899. https://doi.org/10.1109/IEEM.2009.5373201
[8] Committee on Defense Intelligence Agency Technology Forecasts and Reviews, Avoiding Surprise in an Era of Global Technology Advances, vol. 48, no. 9. 2005.
[9] E. Danneels, “Disruptive technology reconsidered: A critique and research agenda,” J. Prod. Innov. Manag., vol. 21, no. 4, pp. 246–258, 2004. https://doi.org/10.1111/j.0737-6782.2004.00076.x
[10] B. Buchanan and R. Corken, “A toolkit for the systematic analysis of patent data to assess a potentially disruptive technology,” 2010. https://assets.publishing.service.gov.uk/...informatic-techtoolkit.pdf
[11] Schmoch U., “Double-boom cycles and the comeback of science-push and market-pull”, Fraunhofer Institute for Systems and Innovation Research, Karlsruhe, Germany (Elsevier). Research Policy 36 (2007) 1000-1015. https://www.academia.edu/29047645/
Скопировать постоянный линк