Компании нужен враг
Мы представляем компанию как сумму ценностных предложений, адресованных её стейкхолдерам, располагающимся на макро- и микро-уровнях внешней среды, а также внутри её самой. Таким образом мы («мы» - это VVSC) соединяем стратегию с маркетингом, а также пытаемся распространить практику последнего на функциональные области, традиционно с маркетингом никак не связанные (например, производство, закупки и финансы). Это, в свою очередь, позволяет применить ценностное (по сути – продуктовое) мышление далеко за границами мира lean-стартапов с IT-генезисом, а именно – в любой отрасли.
Но «компания-сумма ценностных предложений» не должна восприниматься однобоко – исключительно как провайдер добра (то есть, чего-то полезного, хорошего, обезболивающего), который обменивает его у своих стейкхолдеров на выручку, репутацию, протекцию и т.п. Это восприятие, по нашему мнению и опыту, в длинном периоде фатально, потому что стратегически нацелено не на выживание, а на, выражаясь языком эволюционной биологии, размножение. Среди стейкхолдеров компании множество её явных или скрытых врагов, с которыми отношения сотрудничества по модели «ты мне, я тебе» попросту невозможны. Мы называли их раньше «отрицательные стейкхолдеры», помещая под этот заголовок конкурентов, регуляторов, хакеров, сотрудников отдела продаж, уводящих за собой клиентов, и прочих индивидуумов и групп, наносящих в своей явной или скрытой роли ущерб компании.
Но «отрицательный стейкхолдер», похоже, недостаточно убедительный термин для продвижения в предпринимательской среде стратегического мышления, основанного на примате выживания, а не приобретения выгоды. Неопределённость, о которой говорят из каждого утюга, и в которой, вроде бы, очевидно нужно прежде всего выжить, на деле слишком неопределённа, чтобы наполнить идею выживания конкретными стратегическими решениями. Вот и доминируют в советах директоров замыслы сержантского масштаба типа «переждать», «сократить» или «уйти вниз по цене».
Для активной стратегии выживания в неопределённости компании нужен враг. Враги. Найти их легко, они щедро рассыпаны по бизнес-экосистеме и внутренним подразделениям. В онтологии мира, где компания – сумма ценностных предложений для стейкхолдеров, её враг – это стейкхолдер, от которого зависит её стратегическая автономия. Раз так, то, согласно примату выживания, главная цель стратегии – достичь независимости от этого стейкхолдера. Это минимакс, то есть, наилучший исход из худших, рациональная цель, предполагающая активную и умную стратегию. Стремиться поставить врага в зависимость от нас или вовсе устранить из числа релевантных для компании игроков внешней или внутренней среды – это избыточные цели, способные подорвать ресурсы и исказить восприятие стратегом бизнес-контекста, сместив его мышление от баланса сотрудничества и конфликта к чистому конфликту. Не надо звереть.
Если достижение стратегической независимости от врага (то есть, минимакс) – главная цель бизнеса, то все прочие «традиционные» цели оказываются на ступень ниже по приоритетности. И это, на мой взгляд, рациональная иерархия в принципе, а не только в острые периоды внешней неопределённости. Стратегическое мышление должно быть, в первую очередь, направлено на идентификацию врагов в неизбежном будущем и в его сценарных вариациях с последующей выработкой способов борьбы с ними. И здесь к услугам компании весь арсенал «быстрых» и «медленных» стратегий: от основанного на петле Бойда (OODA) перехвата инициативы – и это, пожалуй, лучший инструмент активного действия в остро-неопределённых условиях, - до ресурсного противостояния по заветам Брюса Хендерсона (матрица BCG) и Роберта Макнамары (война во Вьетнаме).
Информационное фуражирование
Информационное фуражирование (information foraging) - концепция, описывающая поведение человека при поиске информации. Её в конце 1990-х предложили сотрудники Xerox PARC Питер Пиролли и Стюарт Кард [1]. Пиролли и Кард вдохновлялись теорией фуражирования пищи [2], которую биологи Роберт Макартур и Эрик Пианка разработали в 1960-х, чтобы понять, как действуют животные в процессе поиска еды, и есть ли в их поведении какие-либо стратегии. Теорию информационного фуражирования Пиролли и Карда полезно иметь в виду при работе с техникой “поддержки” в маркетинговых коммуникациях (см. эссе VVSC “Четыре техники маркетинговых коммуникаций” [3]).
В основе биологической теории фуражирования лежит оценка затрат и выгод для достижения цели, где затраты - это количество ресурсов (в том числе, времени), потребляемых при выполнении выбранной деятельности, а выгода - то, что получено в результате этой деятельности.
В случае охотящегося, например, мангуста, речь идёт о времени и усилиях, которые расходуются на поиск, преследование, и обработку добычи, и об энергии, которую можно получить, съев её. То есть, эффективность охоты прямо пропорциональна приобретённым калориям и обратно пропорциональна затраченному времени и усилиям.
Формула эффективности действий человека при “охоте” за информацией идентична уравнению поиска еды мангустом, считают Пиролли и Кард. Люди оптимизируют своё поведение, сопоставляя ценность полученной информации со временем и усилиями, затраченными на её поиск и освоение.
Три наших тезиса о практическом применение теории информационного фуражирования в работе с маркетинговыми коммуникациями таковы:
- Человек в процессе поиска информации постоянно делает выбор. Какую информацию искать? Нужно ли оставаться на текущей странице? Нужно ли искать дополнительную информацию? Когда нужно прекратить поиск? Важно хорошо разобраться в том, что влияет на его выбор. Как он оценивает пользу от информации? Есть ли моменты, когда он чувствует, что зря тратит время? (Берем подопытных их числа целевой аудитории (ЦА), наблюдаем за процессом поиска информации).
- В охоте за информацией человек полагается на “информационный запах” - индикатор близости “добычи” (то есть, ценной информации). Нужно понять, что является таким индикатором на каждом этапе поиска информации. Так мы получим ответ на вопрос о том, что нужно сделать заметным на сайте/в посте/рекламе/скрипте и пр. (Берем подопытных из числа ЦА, проводим глубинные интервью).
- Так же, как хищник всегда сделает выбор в пользу добычи, которую легче догнать или найти, человек сделает выбор в пользу источника информации, который легче обработать. Поведенческая стратегия при поиске информации всегда будет корректироваться в сторону сокращения времени и усилий. Полезная практика для бизнеса - сравнивать с позиции клиента свои коммуникации с теми, которые попадают в зону внимания потенциального клиента на каждом этапе выбора и оценки. (Тут нужно опять мучать подопытных, но можно сначала самому пройти путь клиента в каналах коммуникации конкурента и своих, решая конкретную задачу).
Три ремарки
В будущем прошлого намного больше, чем мы, больные неоманией, привыкли допускать. Когда кажется, что рушится всё, а впереди – туман неопределённости, стоит обернуться и увидеть многочисленные линии долгоживущих трендов, которые годы, десятилетия, а то и столетия формировали завтрашний день компании и её окружения. Эти линии тянутся в будущее и сейчас, а самые надёжные из них – самые старые. Это «вечные ценности», и именно они – причина, по которой стратегия остаётся актуальной в переломные моменты. Не следует недооценивать количества прошлого в будущем. Нужно разглядеть это прошлое и сделать основой стратегии.
Дальше. Компания – сумма ценностных предложений, адресованных всем её стейкхолдерам. В основе этого взгляда – теория стейкхолдеров философа Эдварда Фримена (Edward Freeman) [1]: компании и их окружение это «инфраструктура», в которой сотрудничают стейкхолдеры, – люди, играющие ситуационные роли ради достижения ролевых целей. Этика в теории стейкхолдеров выступает главным мерилом бизнеса: она направляет стратегию, ограничивает маркетинг, пронизывает своими критериями все прочие функциональные области. И речь не только о «практической» этике – как не навредить в конкретных транзакциях, – но о философии добра и зла в целом. Бизнес, лучше отражающий в своих ценностных предложениях моральные установки стейкхолдеров, обладает фундаментальным превосходством над соперниками. А в аморальные времена «новые возможности» по большей части аморальны, и об этом полезно помнить.
И третье. Не следует ждать добра от неопределённости. Принять медведя за камень не то же самое, что принять камень за медведя.

Фрактал
Оглянись на прошедшее: сколько переворотов пережили уже государства! Можно предвидеть и будущее. Ведь оно будет совершенно в том же роде и не выйдет из ритма происходящего ныне. Поэтому и безразлично, будешь ли ты наблюдать человеческую жизнь в течение сорока лет или же десяти тысяч лет. Ибо что ты увидишь нового?
Марк Аврелий. Наедине с собой. Размышления. Книга седьмая, XLIX.
***
В этой публикации две части. В первой демонстрируем сценарии макро-уровня, во второй говорим несколько слов о методе их создания и обновления.
Часть 1. Слайд «2026»
Сценарный горизонт 5 лет. Макро-уровень.
Критические неопределенные факторы, в которых строится сценарное поле: «внутренняя эффективность государства» и «внешнее давление на государство». Каждый фактор наделён двумя состояниями: «снижается» и «сохраняется или растёт».
В центре сценарного поля располагаются характеристики, общие для всех сценариев – черты «неизбежного будущего».
К «неизбежному будущему» примыкают четыре квадранта сценарного поля. Внутри них показаны альтернативные траектории ВВП, а в выносках даны краткие текстовые сценарии.
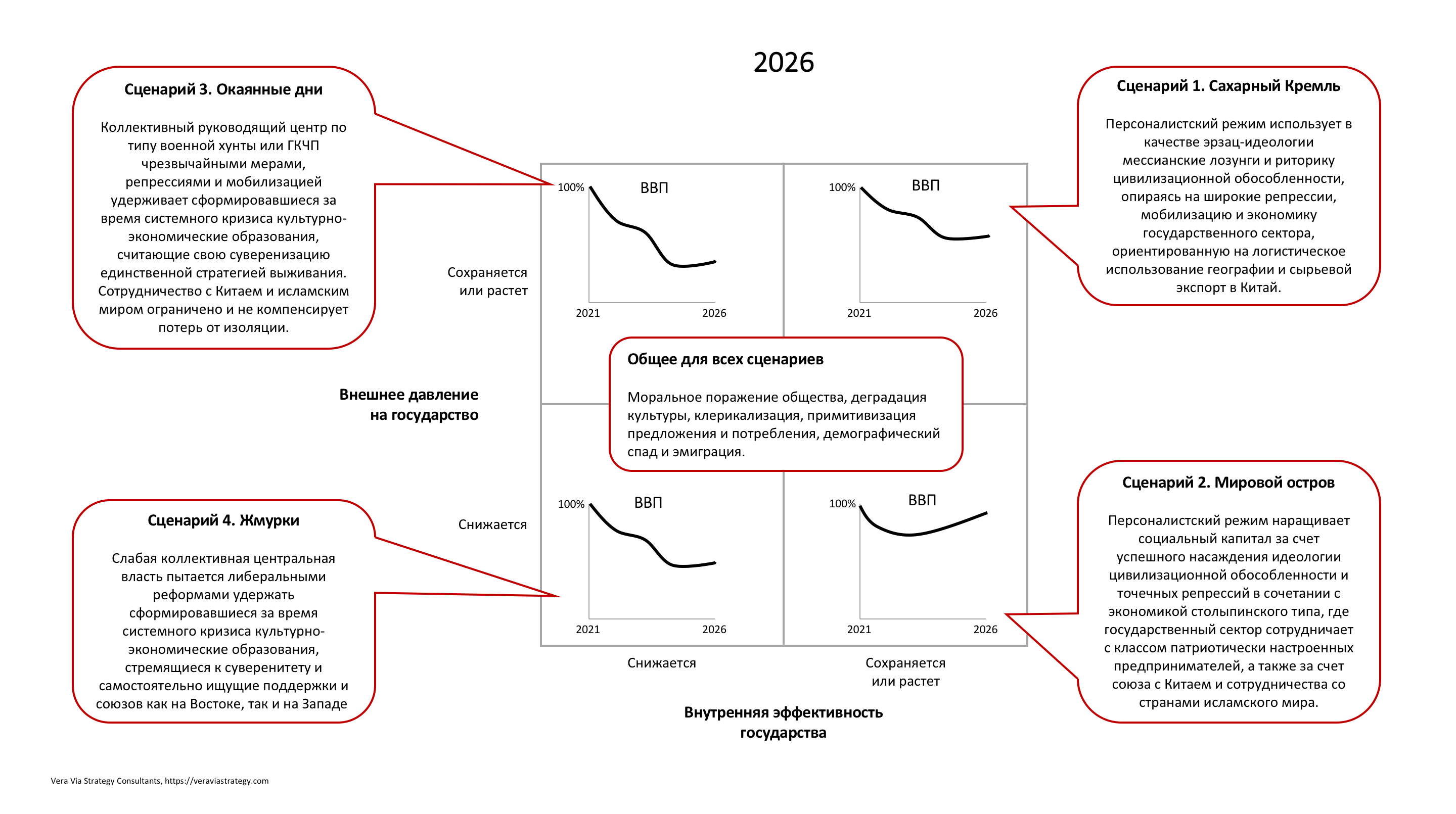
Общее для всех сценариев («неизбежное будущее»): моральное поражение общества, деградация культуры, клерикализация, примитивизация предложения и потребления, демографический спад и эмиграция.
Сценарий 1. Сахарный Кремль (внешнее давление на государство и его внутренняя эффективность сохраняются на текущем уровне или растут).
Персоналистский режим использует в качестве эрзац-идеологии мессианские лозунги и риторику цивилизационной обособленности, опираясь на широкие репрессии, мобилизацию и экономику государственного сектора, ориентированную на логистическое использование географии и сырьевой экспорт в Китай.
Сценарий 2. Мировой остров (внешнее давление снижается, внутренняя эффективность сохраняется на текущем уровне или растёт).
Персоналистский режим наращивает социальный капитал за счет успешного насаждения идеологии цивилизационной обособленности и точечных репрессий в сочетании с экономикой столыпинского типа, где государственный сектор сотрудничает с классом патриотически настроенных предпринимателей, а также за счет союза с Китаем и сотрудничества со странами исламского мира.
Сценарий 3. Окаянные дни (внешнее давление сохраняется на текущем уровне или растёт, внутренняя эффективность снижается).
Коллективный руководящий центр по типу военной хунты или ГКЧП чрезвычайными мерами, репрессиями и мобилизацией удерживает сформировавшиеся за время системного кризиса культурно-экономические образования, считающие свою суверенизацию единственной стратегией выживания. Сотрудничество с Китаем и исламским миром ограничено и не компенсирует потерь от изоляции.
(В этом сценарии глубина падения ВВП отсылает к условному историческому аналогу – пятилетнему периоду 1916-1921 гг.)
Сценарий 4. Жмурки (внешнее давление на государство и его внутренняя эффективность снижаются).
Слабая коллективная центральная власть пытается либеральными реформами удержать сформировавшиеся за время системного кризиса культурно-экономические образования, стремящиеся к суверенитету и самостоятельно ищущие поддержки и союзов как на Востоке, так и на Западе.
Сейчас приведённые выше четыре сценария следует воспринимать как равновероятные. Такова особенность метода – в нём мы имеем дело с критически важными (то есть, определяющими главные контуры будущего), но неопределёнными факторами. Впрочем, утверждение, что перед нами четыре взаимоисключающих, но равновозможных версии завтрашнего дня, в обычных условиях звучащее академической абстракцией, в ситуации экзистенциальных ставок оказывается не только выпукло-понятным, но и путеводным: хочешь повысить свои шансы на выживание, готовься одновременно к четырём исходам.
Что дальше?
Часть 2. Слайд «Сценарии будущего как фрактал»
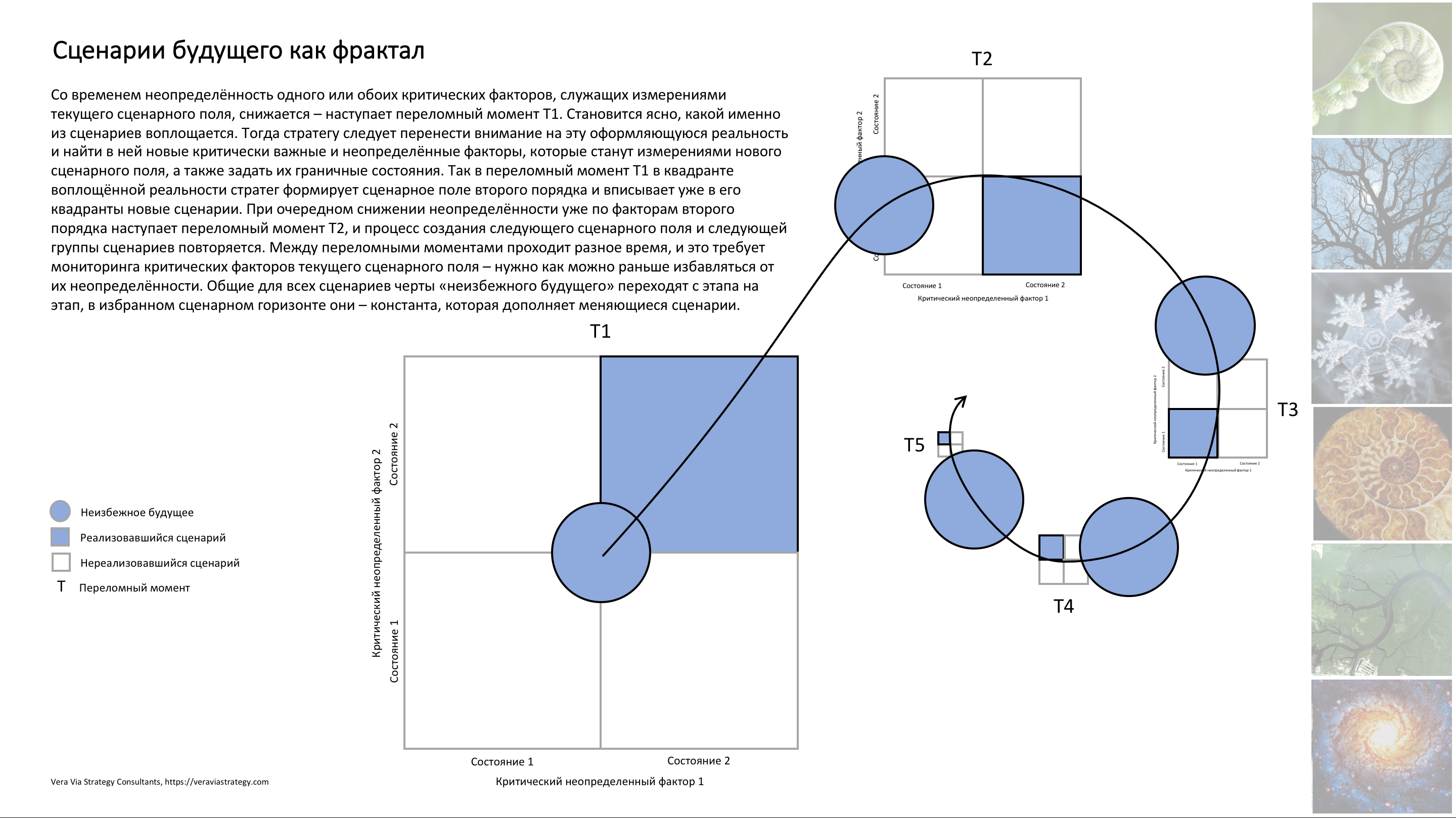
Метафора фрактала – самоподобной функции – хорошо описывает наш путь преодоления неопределённости в исследованиях будущего по мере продвижения в него.
Со временем неопределённость одного или обоих критических факторов, служащих измерениями текущего сценарного поля, снизится – наступит переломный момент Т1. Станет ясно, какой именно из сценариев воплощается. Тогда мы перенесём внимание на эту проступающую реальность и найдём в ней новые критически важные и неопределённые факторы, которые станут измерениями её нового сценарного поля, а также зададим их граничные состояния. Так в переломный момент Т1 в мы сформируем квадранте воплощённой реальности сценарное поле второго порядка и впишем уже в его квадранты новые сценарии. При очередном снижении неопределённости уже по факторам второго порядка наступит переломный момент Т2, и мы повторим процесс создания очередного сценарного поля и очередной группы сценариев. Между переломными моментами проходит разное время, и это требует мониторинга критических факторов текущего сценарного поля – нам нужно как можно раньше избавляться от их неопределённости… Остаётся добавить, что общие для всех сценариев черты «неизбежного будущего» мы будем переносить с этапа на этап, в избранном пятилетнем горизонте они – константа, которая дополняет меняющиеся сценарии.
Сценарное планирование via negativa
Нельзя предсказать, что будет НОВОГО в мире, скрывающемся за дальним временным горизонтом. Но вполне можно выявить СТАРОЕ, которое в нём сохранится. То есть, возможно достоверно описать будущее путём удаления всего, что умрёт до его наступления. У такой задачи есть решение, и оно – в знании человеческой истории, во внимательном взгляде в прошлое ради оценки технологий (в самом широком значении этого термина) на устойчивость к главному стрессору – времени. Если что-то прожило пять тысяч лет, то, скорее всего, оно проживёт ещё очень-очень долго – люди совсем не зря доверяют ему. А инновация, лет пяти от роду, пытающаяся потеснить это пятитысячелетнее старое, почти наверняка не просуществует и до конца декады.
Инновации – всегда субститут тому, что было до них. Мы вроде бы это знаем, но беда в том, что, строя прогнозы, мы игнорируем значение разницы в возрасте между технологиями-инкумбентами (старыми) и технологиями-челленджерами (новыми). А если и обращаем на это внимание, то делаем ошибочный вывод: новое всегда побеждает старое. Не всегда, напротив – почти никогда! Одержимые неоманией, мы не читаем книг, не смотрим в прошлое, не видим, что новое способно победить только другое новое. Чем больше разница в возрасте, тем меньше шансов у бросающей вызов инновации. Нельзя с наскока одолеть то, что эволюционно на порядки более значимо для человека. Можно победить лишь что-то сравнимое по возрасту, и именно это происходит вокруг нас: технологии-дети сражаются с ровесниками-субститутами, миллионы мелких схваток кишат у ног непоколебимых столетних трендов, тысячелетних традиций, пятитысячелетних устоев.
Можно ли предсказать, кто из юных субститутов победит и укрепится в мире за далёким временным горизонтом? Нет. Невозможно создать ПОЗИТИВНЫЙ образ завтрашнего дня. Нельзя угадать НОВОЕ в будущем. Но НЕГАТИВНОЕ описание будущего сделать можно – в нём не придётся иметь дело с непредсказуемостью и гаданиями. Негативное – не значит алармистское и пессимистическое. Негативное – значит созданное via negativa, то есть, путём вычитания из сценариев будущего всего, что сегодня не накопило эволюционной мощи. Конечно, при таком подходе мы вычтем что-то новое, что победит в борьбе и будет присутствовать в реальном будущем, когда оно наступит. Но эта ошибка совершенно не важна. Важно, что мы сохраним в прогнозе то, что нам хорошо известно и что выживет наверняка.
Нежизнеспособных экспериментов неизмеримо больше, и именно они – такие перспективные и «научно-обоснованные» сегодня, но мёртвые завтра – превращают позитивные нарративы про то, что НОВОГО ждёт нас в будущем, в моментально устаревающую, никогда не сбывающуюся, безответственную чушь. Негативная же картина мира, содержащая в себе только то, что из СУЩЕСТВУЮЩЕГО СЕЙЧАС сохранится и в будущем, даёт рациональной (то есть, во всех действиях руководствующейся правилом «сначала – выживание») компании реальную долгосрочную ценность: и надёжную основу для 9/10 стратегии, и sandbox в 1/10 ресурсов для множества мелких и сколь угодно безумных инновационных опытов.
И ещё – негативное сценарное планирование тем более точно, чем длиннее его горизонт.